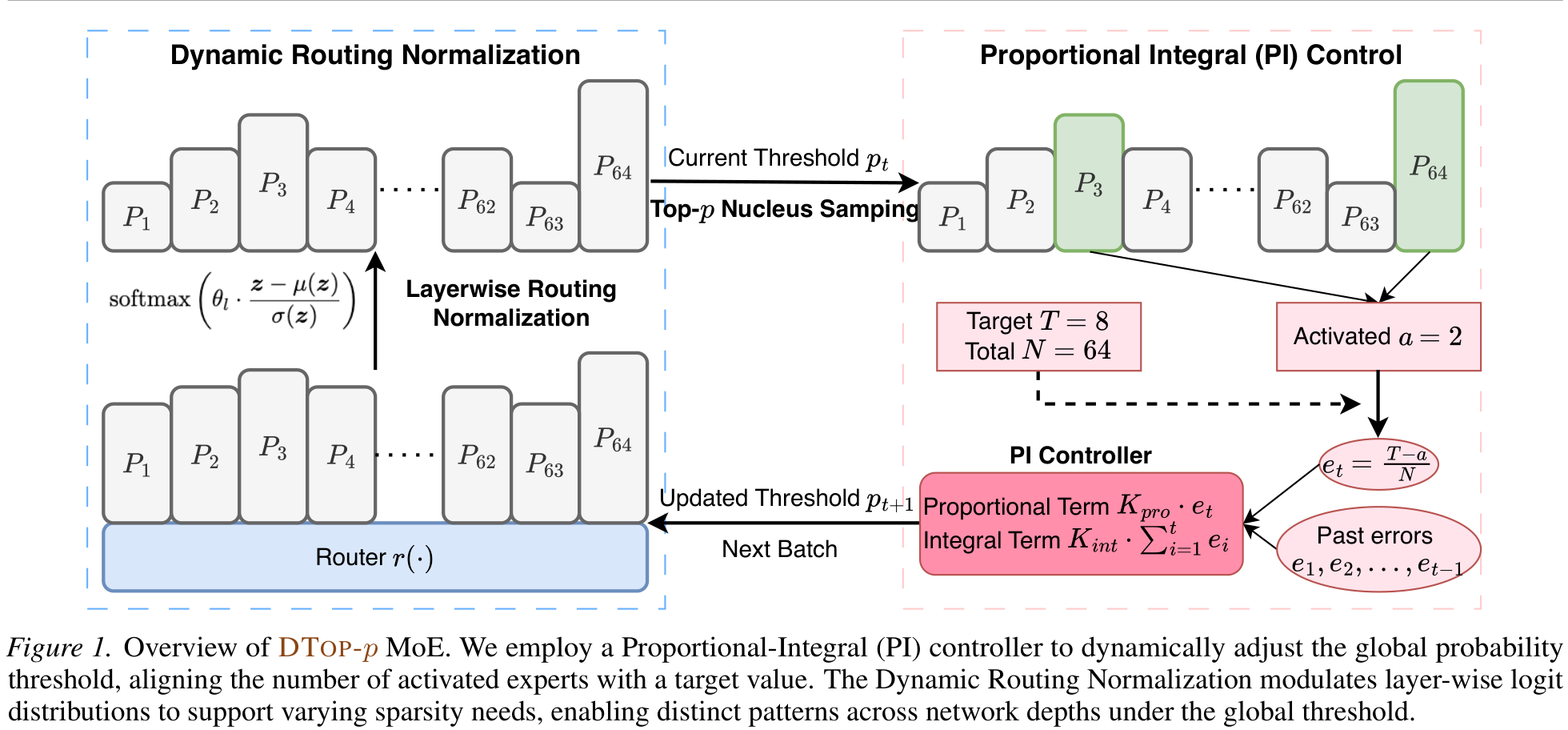
A Proportional-Integral (PI) controller makes the global Top-p threshold effectively learnable to hit a target expert count, while Dynamic Routing Normalization lets each layer choose its own sparsity under that single global budget.
A Proportional-Integral (PI) controller makes the global Top-p threshold effectively learnable to hit a target expert count, while Dynamic Routing Normalization lets each layer choose its own sparsity under that single global budget.
Make Top-p routing compute-controllable and more effective than Top-k — with a control-theory twist.
The Top-p threshold is non-differentiable, so it cannot be learned by SGD. DTop-p instead treats target sparsity as a control setpoint.
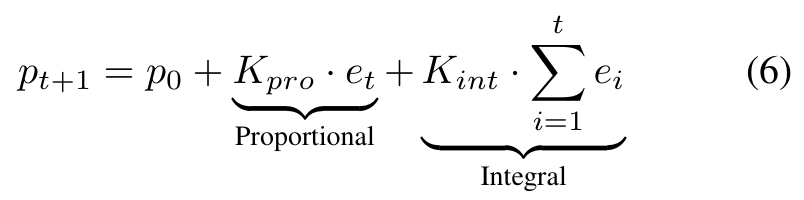
From the sparsity error et = (T−at)/N, the proportional term reacts to deviation and the integral term removes steady-state bias — so the average activated experts converge to the budget T. No gradient on the threshold.
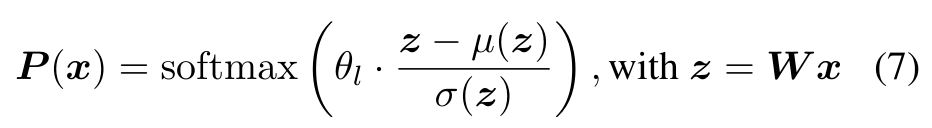
A learnable per-layer scale θl rescales normalized logits: larger θl sharpens (fewer experts), smaller flattens (more experts). Each layer learns a distinct sparsity pattern under one global threshold.
NLP — MoE-1.3B-6.9B-64E8A trained on 100B DCLM tokens.
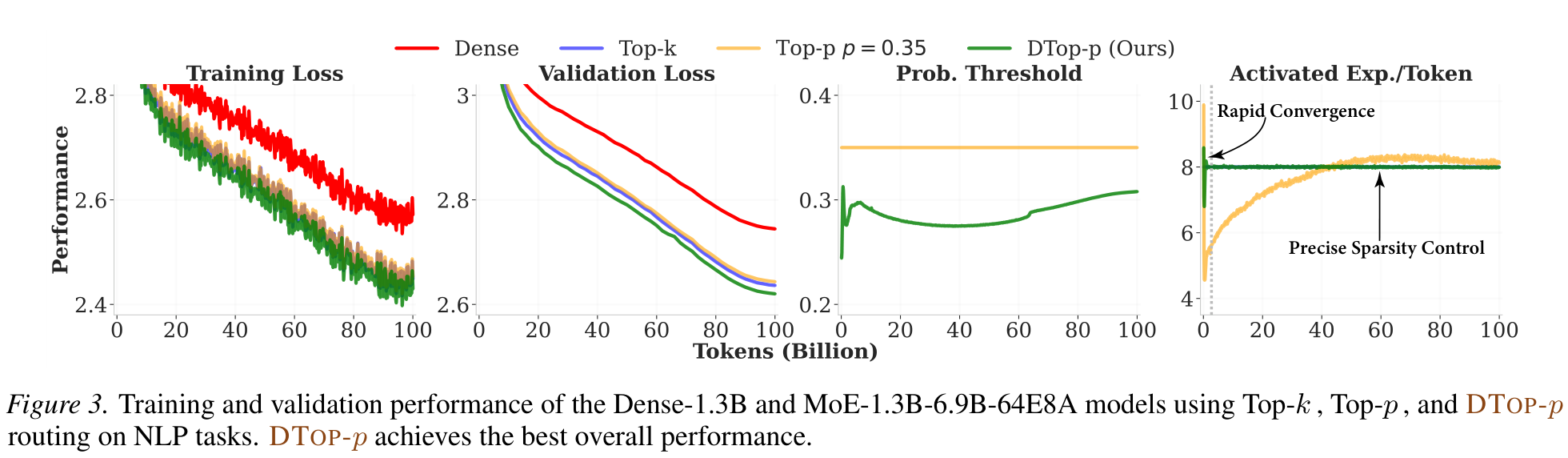
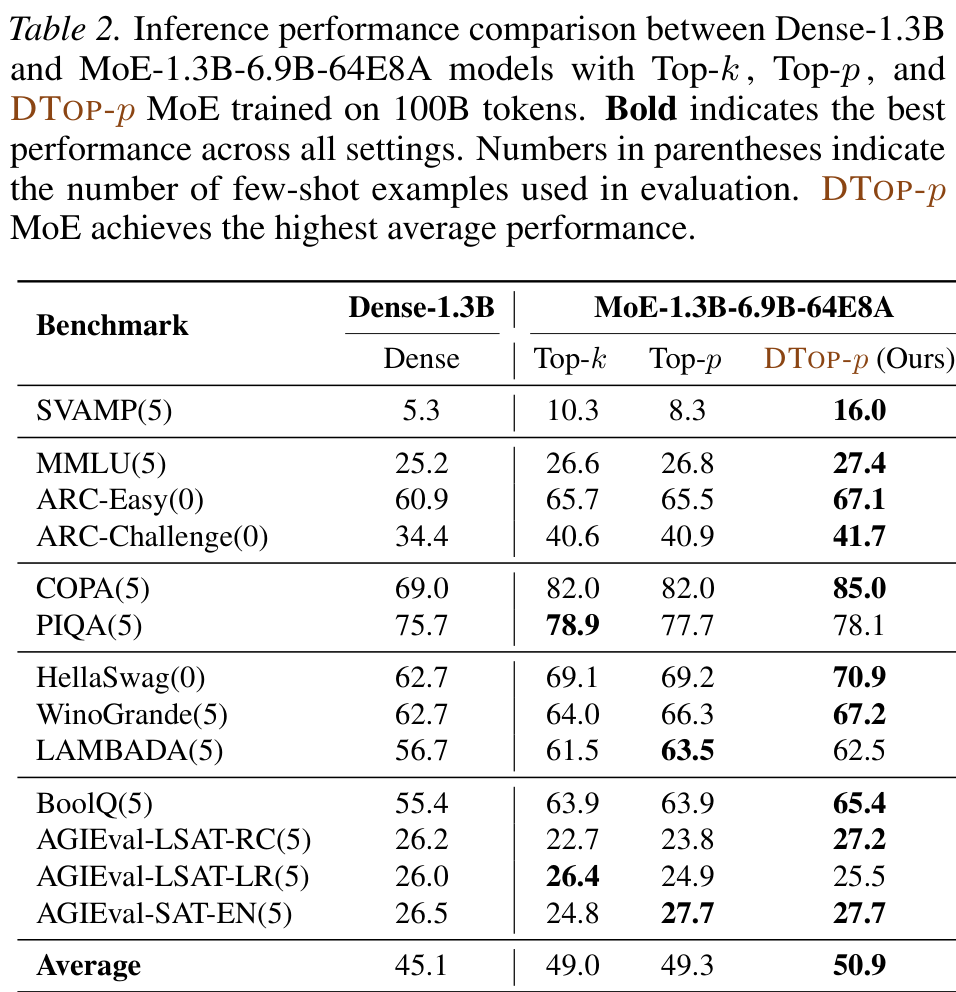
DTop-p reaches the best train/val loss and locks the activated-expert count to T = 8 within ~1B tokens, while fixed Top-p overshoots and oscillates.
Computer Vision — a 64E8A MoE Diffusion Transformer (0.9B active / 3.4B total) trained on 2T pixel tokens.
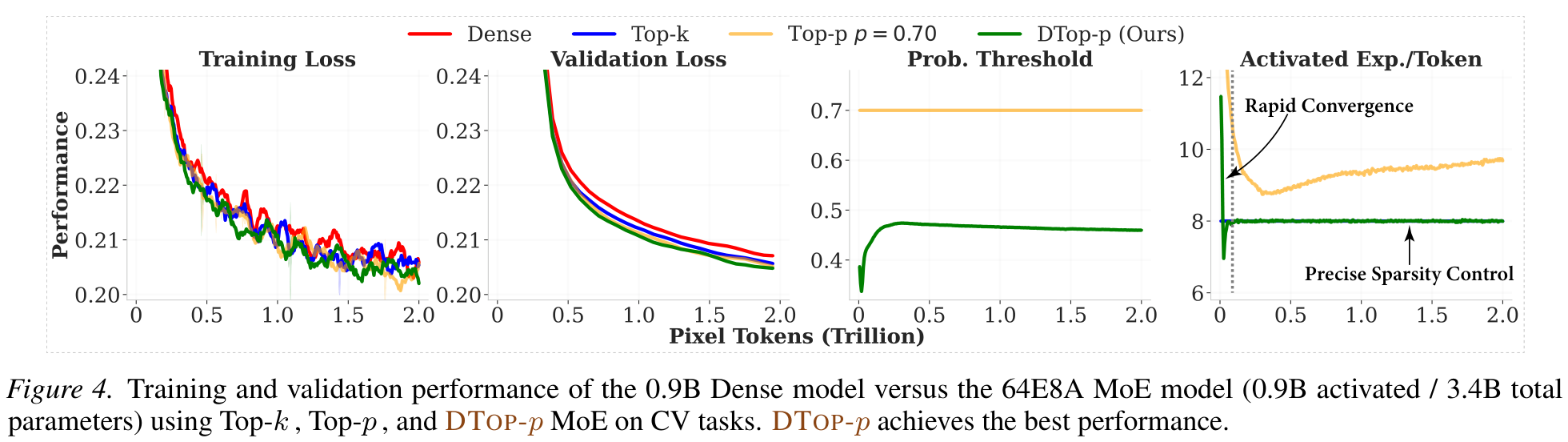
Precise control, adaptive allocation, and the contribution of each component.
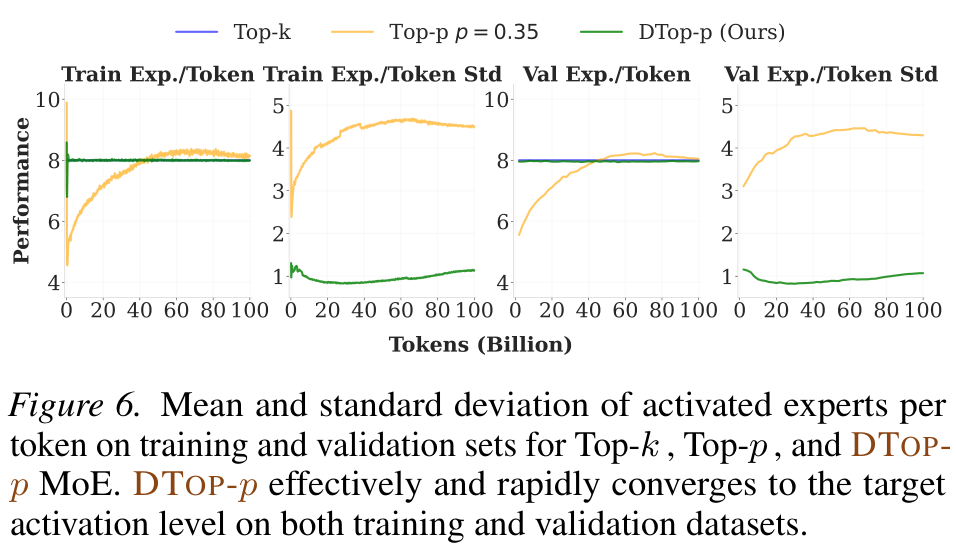
DTop-p converges to T = 8 with low variance (σ ≈ 1); fixed Top-p drifts with σ ≈ 4.
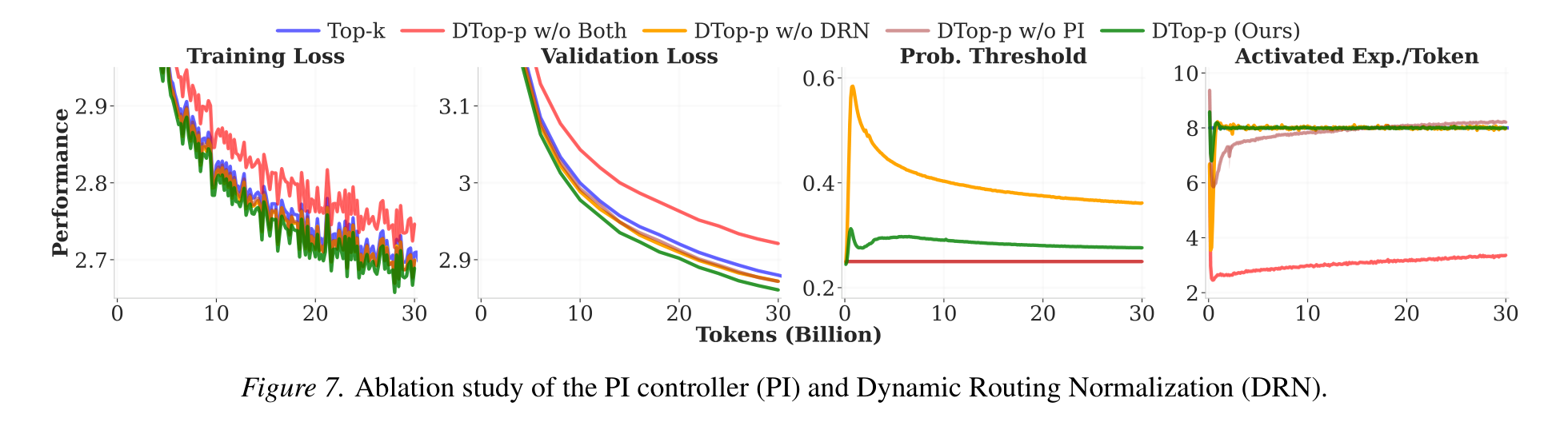
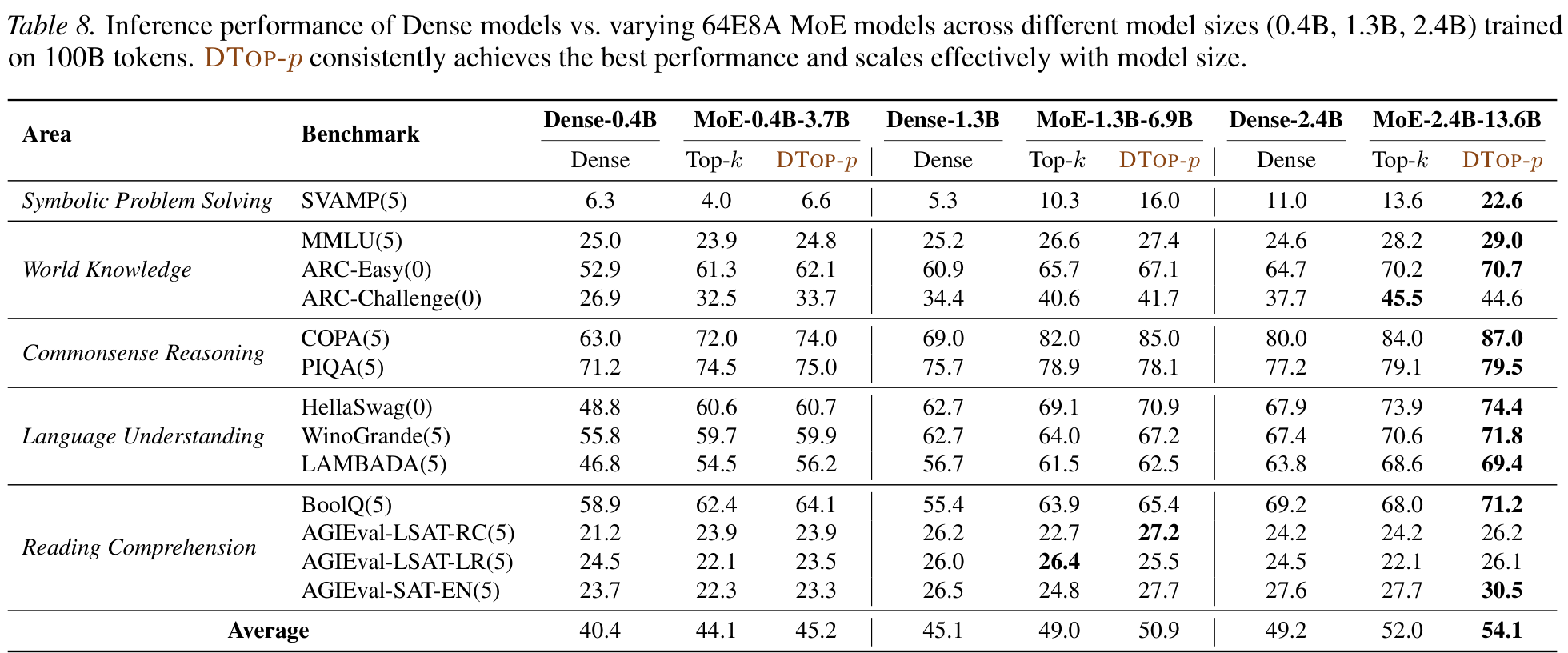
Both the PI controller and DRN are needed for the best result (left); the advantage over Top-k widens with model scale from 0.4B to 2.4B (right).
Everything for the ICML 2026 presentation.
@inproceedings{jin2026dtopp,
title = {{DTop-$p$ MoE}: Sparsity-Controlled Dynamic Top-$p$ MoE
for Foundation Model Pre-training},
author = {Jin, Can and Peng, Hongwu and Xiang, Mingcan and Zhang, Qixin
and Yuan, Xiangchi and Hasan, Amit and Dibua, Ohi and Gong, Yifan
and Kang, Yan and Metaxas, Dimitris N.},
booktitle = {Proceedings of the 43rd International Conference on Machine Learning},
series = {Proceedings of Machine Learning Research},
volume = {306},
year = {2026},
publisher = {PMLR},
address = {Seoul, South Korea}
}