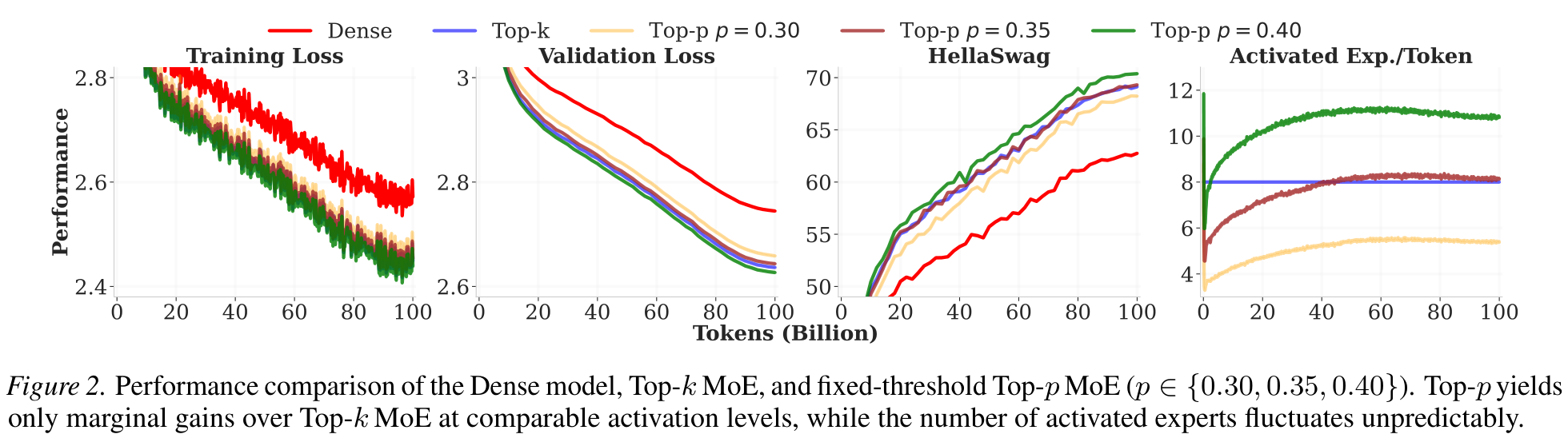
❶ Uncontrolled compute
Activated-expert count fluctuates unpredictably during training — incompatible with strict pre-training FLOP budgets (OOM risk).❷ Hypersensitive to p
p = 0.40 over-activates (>12 experts); p = 0.35 only matches Top-k. Gains are marginal and tuning is costly.DTop-p MoE — ICML 2026Presented by Can Jin3 / 16
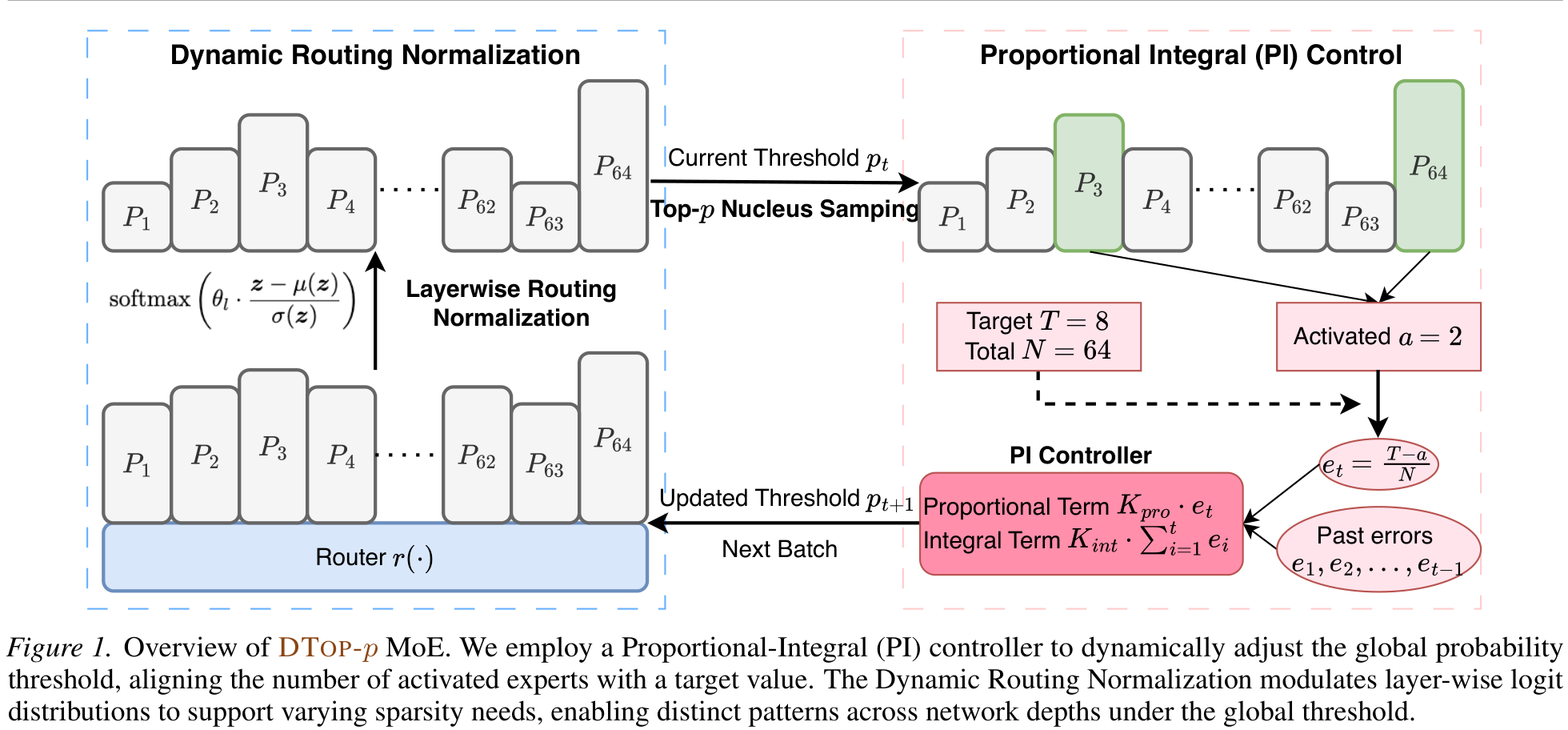
A PI controller adjusts the global probability threshold to hit a target expert count; Dynamic Routing Normalization lets each layer choose its own sparsity under that budget.
DTop-p MoE — ICML 2026Presented by Can Jin5 / 16
Track average activated experts at per batch; define sparsity error et = (T − at) / N. A discrete Proportional-Integral law updates the threshold:
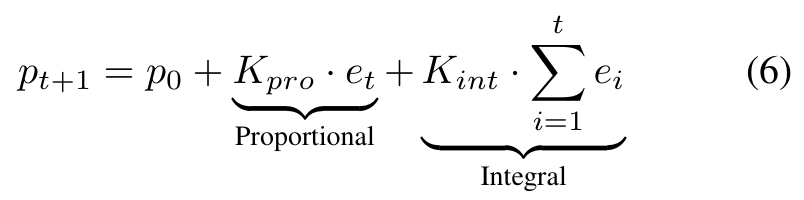
Proportional term
Reacts immediately to the current deviation from target T.Integral term
Accumulates past errors → removes steady-state bias, so at converges to T.Relies on the monotonicity of nucleus sampling: raising p ⇒ more experts. No gradient needed for the threshold.
DTop-p MoE — ICML 2026Presented by Can Jin6 / 16
A single global threshold assumes uniform logit statistics across depth. Instead, normalize each layer's logits and apply a learnable per-layer scale θl:
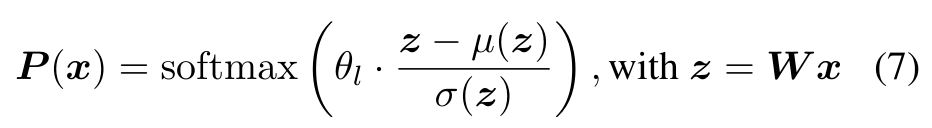
- Large θl → sharper distribution → fewer experts; small θl → flatter → more experts.
- Each layer learns a distinct sparsity pattern while still respecting the single global budget.
DTop-p MoE — ICML 2026Presented by Can Jin7 / 16
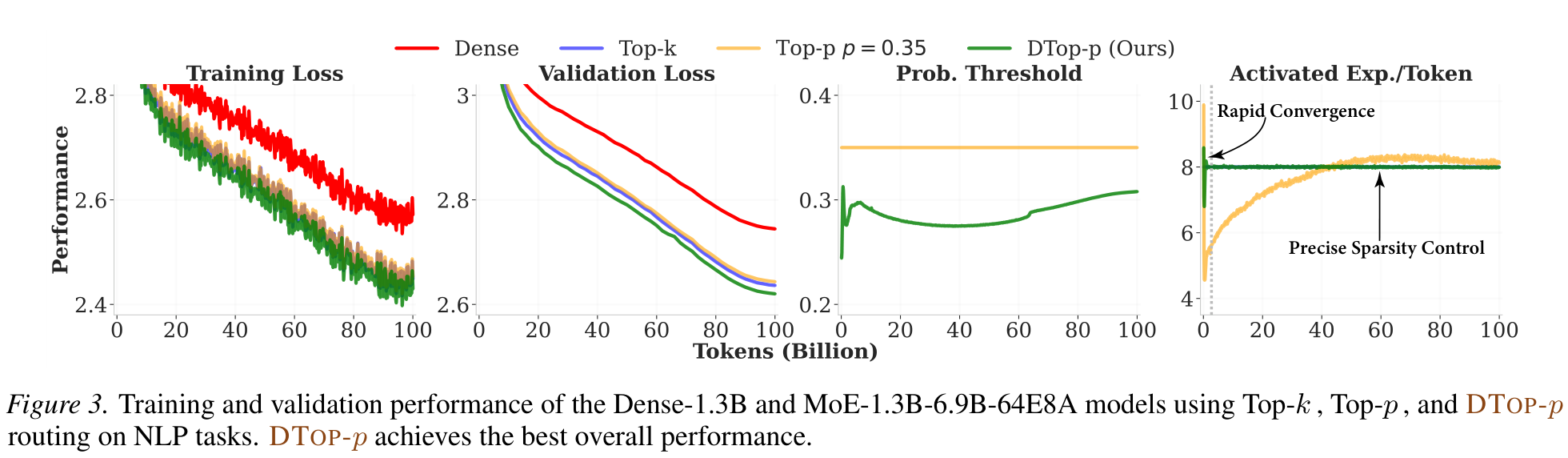
DTop-p reaches the best train/val loss on MoE-1.3B-6.9B-64E8A and locks the activated-expert count to T = 8 within ~1B tokens — fixed Top-p overshoots and oscillates.
DTop-p MoE — ICML 2026Presented by Can Jin8 / 16
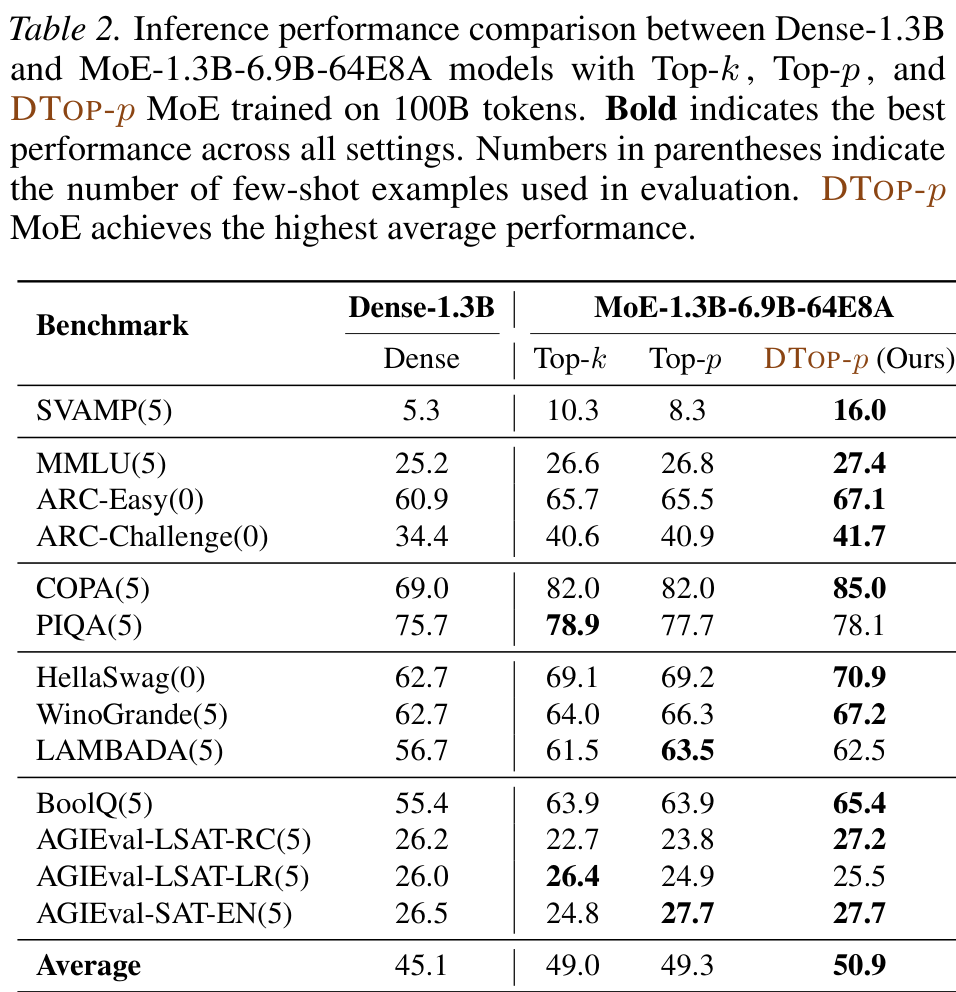
+1.9%
average gain over Top-k MoE
at matched average FLOPs
at matched average FLOPs
- Best average across the 13 zero/few-shot tasks (50.9 vs 49.0 / 49.3).
- Large gains on reasoning: SVAMP +5.7, COPA +3.0 over Top-k.
DTop-p MoE — ICML 2026Presented by Can Jin9 / 16
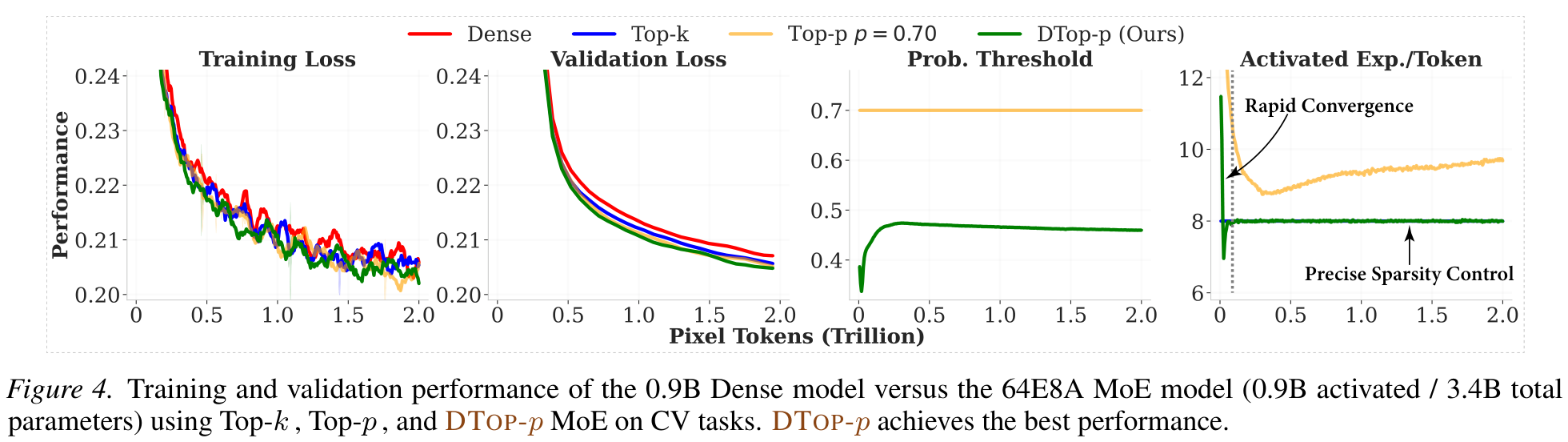
On a 0.9B → 3.4B 64E8A MoE DiT trained on 2T pixel tokens, DTop-p again achieves the lowest validation loss while holding precise sparsity — the method is not NLP-specific.
DTop-p MoE — ICML 2026Presented by Can Jin10 / 16
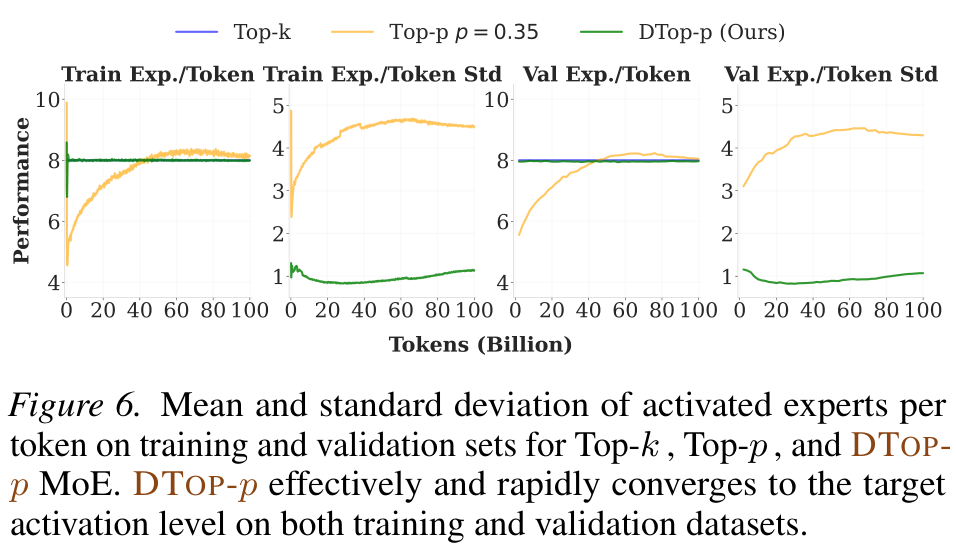
Precise
Converges to T = 8 with low variance (σ ≈ 1); fixed Top-p drifts with σ ≈ 4.Adaptive (hierarchical)
Learns to use fewer experts in shallow layers, more in deep layers — emergent depth-wise specialization.DTop-p MoE — ICML 2026Presented by Can Jin11 / 16
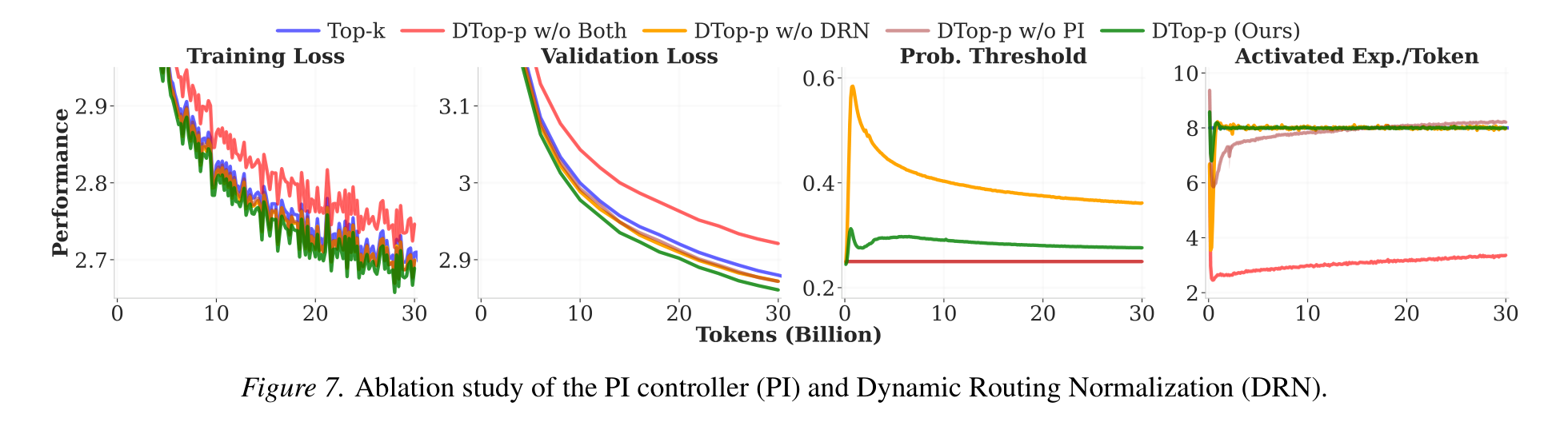
PI controller — without it, sparsity is unregulated and drifts.
DRN — adaptively rescales layer logits; best loss only with both combined.
DTop-p MoE — ICML 2026Presented by Can Jin12 / 16
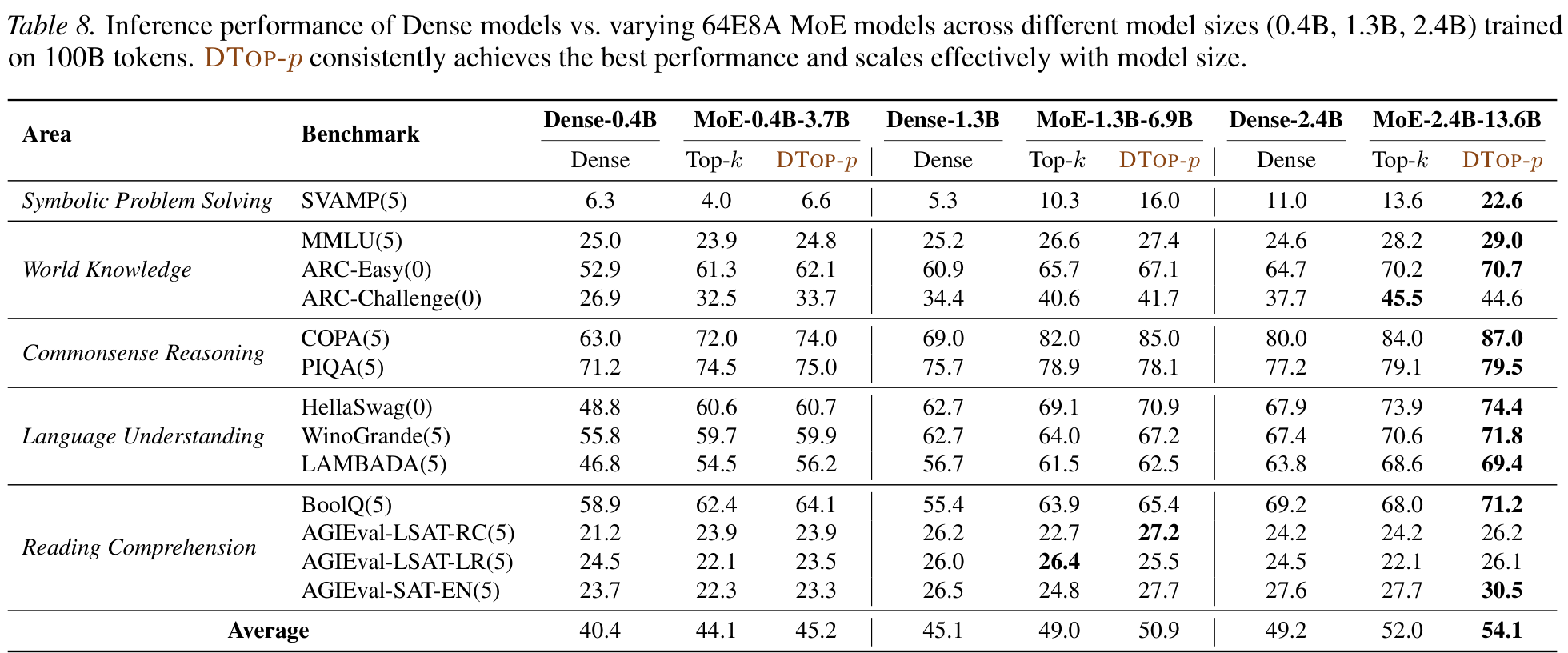
DTop-p wins at every model size — and the advantage over Top-k widens with scale. It also benefits more from finer expert granularity and more training data.
DTop-p MoE — ICML 2026Presented by Can Jin13 / 16

- Forward: per layer, normalize logits (DRN) → nucleus-sample experts at threshold pt.
- Feedback: measure at, compute error, update pt+1 via PI.
- Cost: only a lightweight scalar signal on top of standard MoE training.
DTop-p MoE — ICML 2026Presented by Can Jin14 / 16