Sparse Mixture-of-Experts (MoE) scales model capacity by activating only a few experts per token, decoupling parameters from compute cost. Two routing schemes dominate pre-training:
- Top-k — fixed number of experts per token; ignores token difficulty & layer needs.
- Fixed Top-p — selects experts until cumulative probability exceeds threshold p.
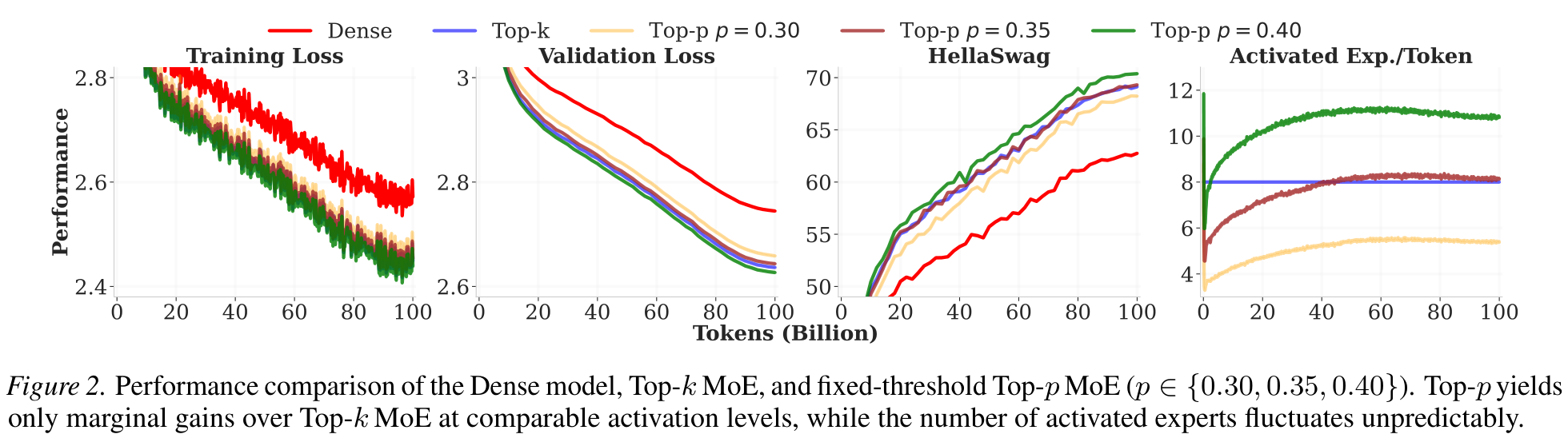
- ❶ Uncontrolled compute: activated-expert count fluctuates unpredictably — incompatible with strict pre-training budgets.
- ❷ Hypersensitive to p: p=0.40 over-activates (>12 experts); p=0.35 only matches Top-k — gains are marginal.
Top-p is inherently adaptive — confident tokens use fewer experts, uncertain tokens recruit more — but the threshold receives no gradient (it only binarizes the mask), so it cannot be learned by SGD.
- Analysis showing fixed-threshold Top-p gives only marginal gains over Top-k with uncontrolled cost.
- DTop-p MoE: a PI-controlled, sparsity-controllable dynamic Top-p with Dynamic Routing Normalization (+ a layer-wise variant).
- Comprehensive study on NLP & CV: better performance and scaling at matched FLOPs.
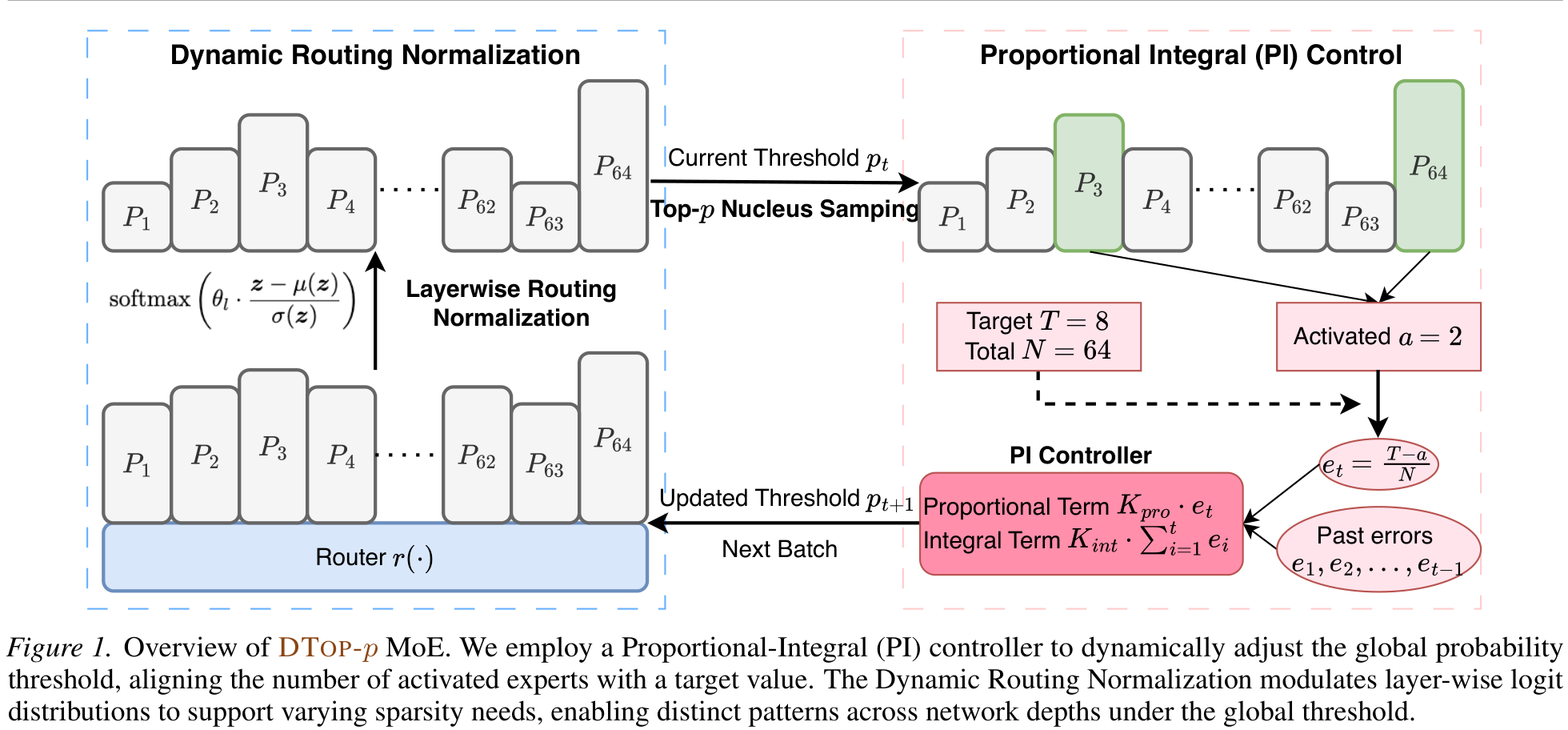
A Proportional-Integral controller adjusts the global threshold p between batches from the sparsity error et=(T−at)/N:
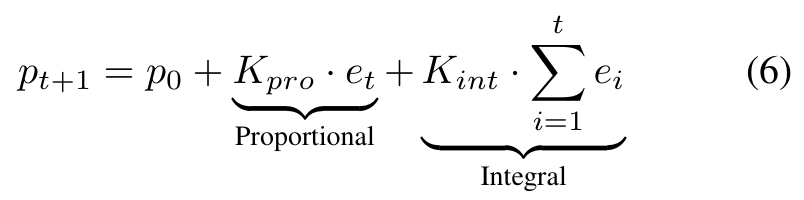
The proportional term reacts to deviation; the integral term removes steady-state bias, driving activated experts at → target T.
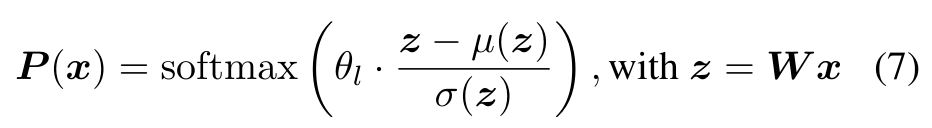
A learnable per-layer scale θl rescales normalized logits, letting each layer sharpen/flatten its routing — enabling distinct sparsity per depth under one global threshold.

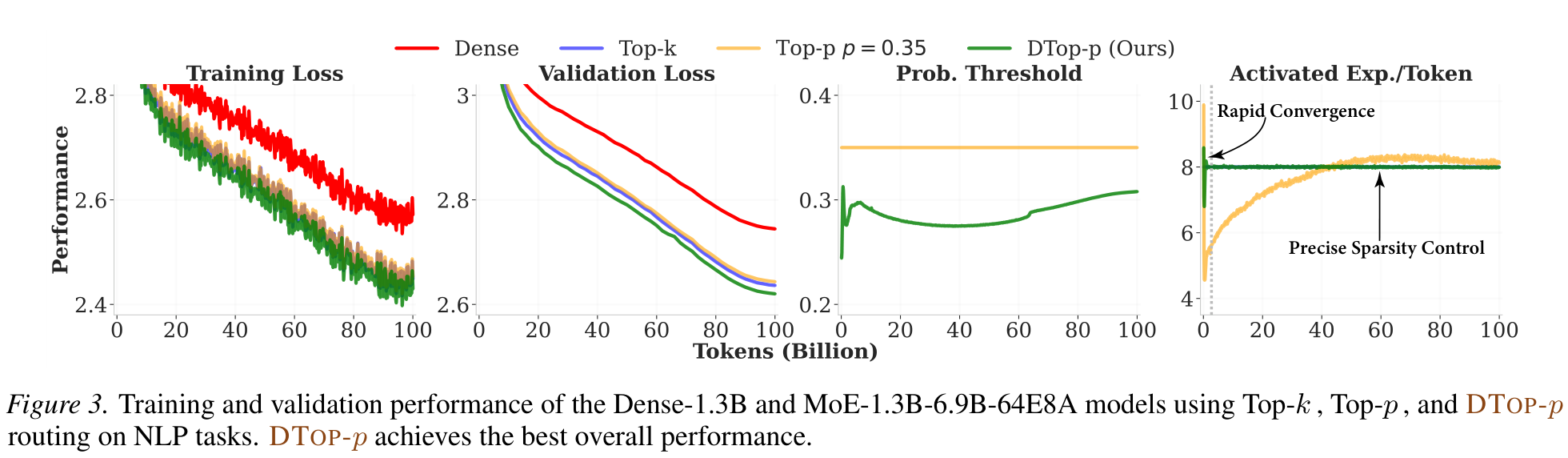
MoE-1.3B-6.9B-64E8A (1.3B active / 6.9B total). DTop-p reaches the best loss and locks sparsity to T=8, unlike fixed Top-p which overshoots.
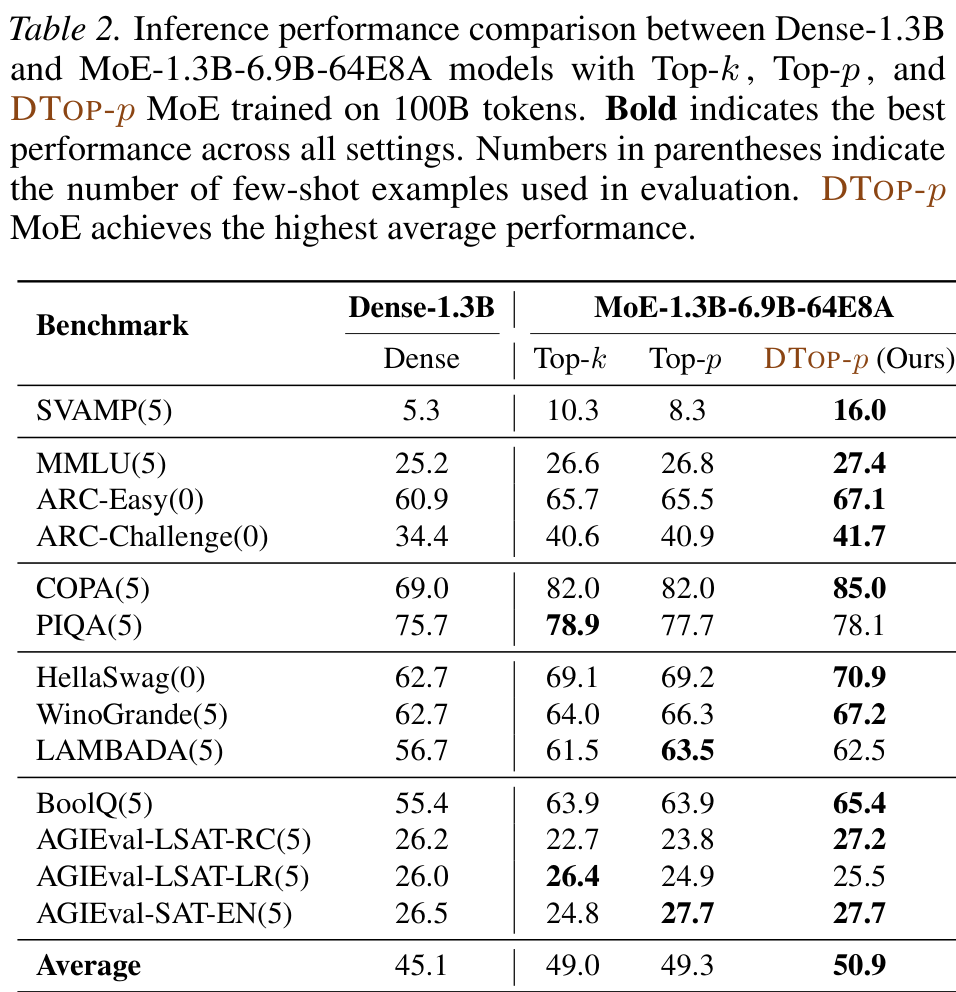
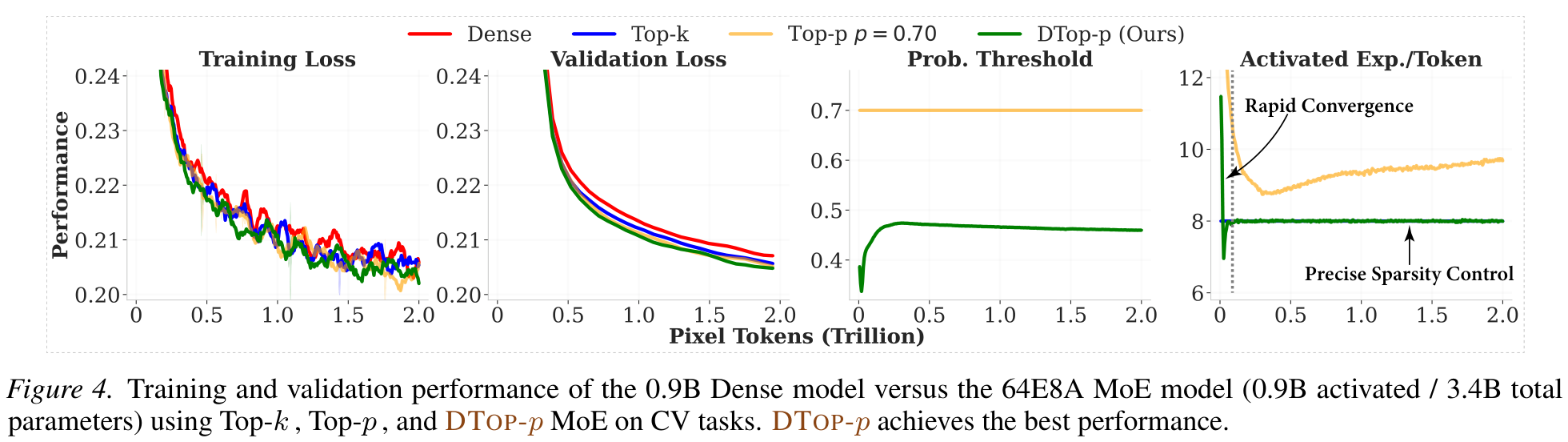
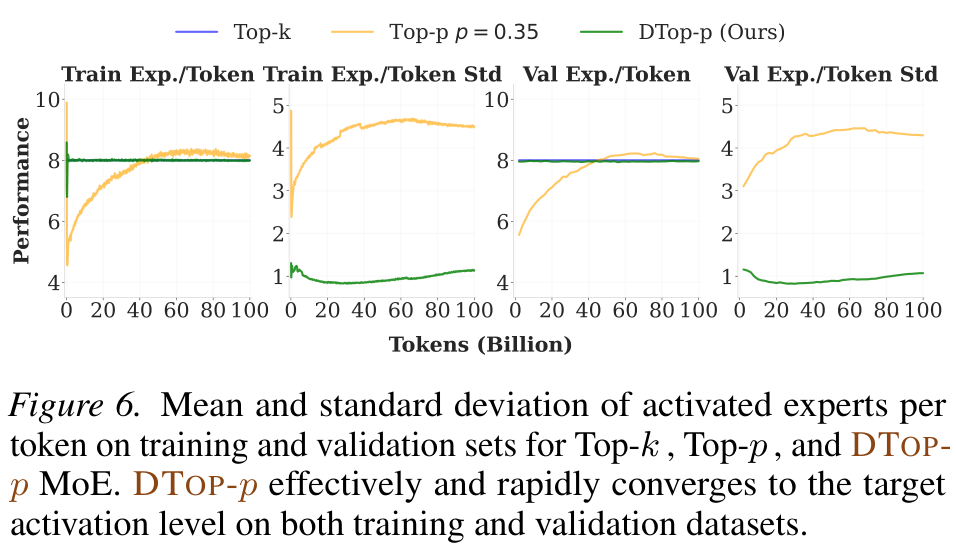
DTop-p converges to T=8 with low variance (σ≈1); fixed Top-p drifts with σ≈4. It activates fewer experts in shallow layers, more in deep layers.
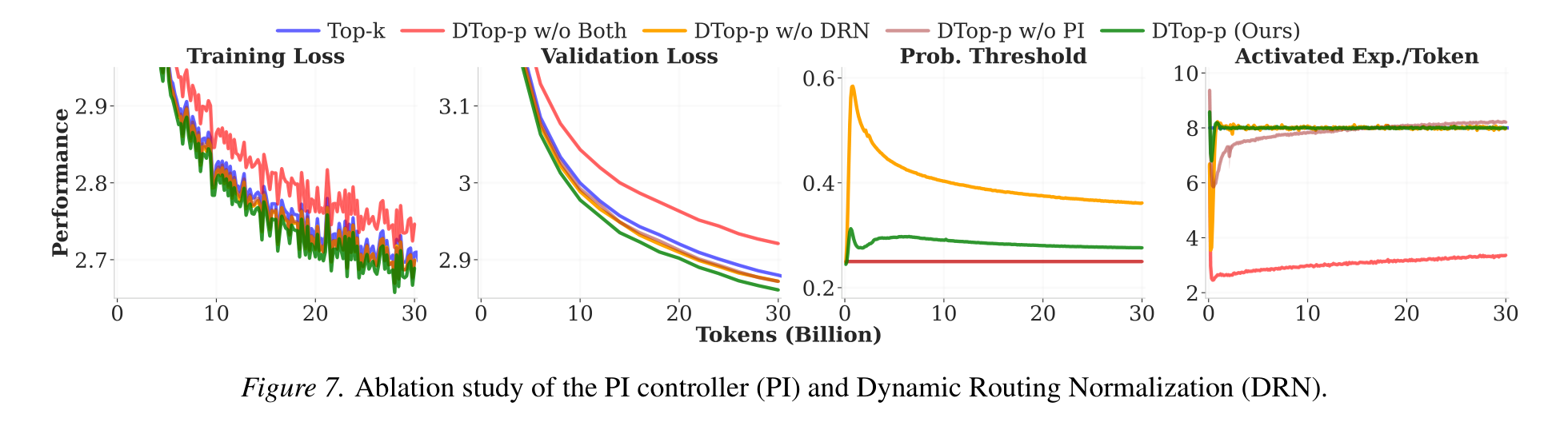
Both components are needed: PI enforces the budget; DRN adaptively rescales layer logits. Together they give the best loss and stable threshold.
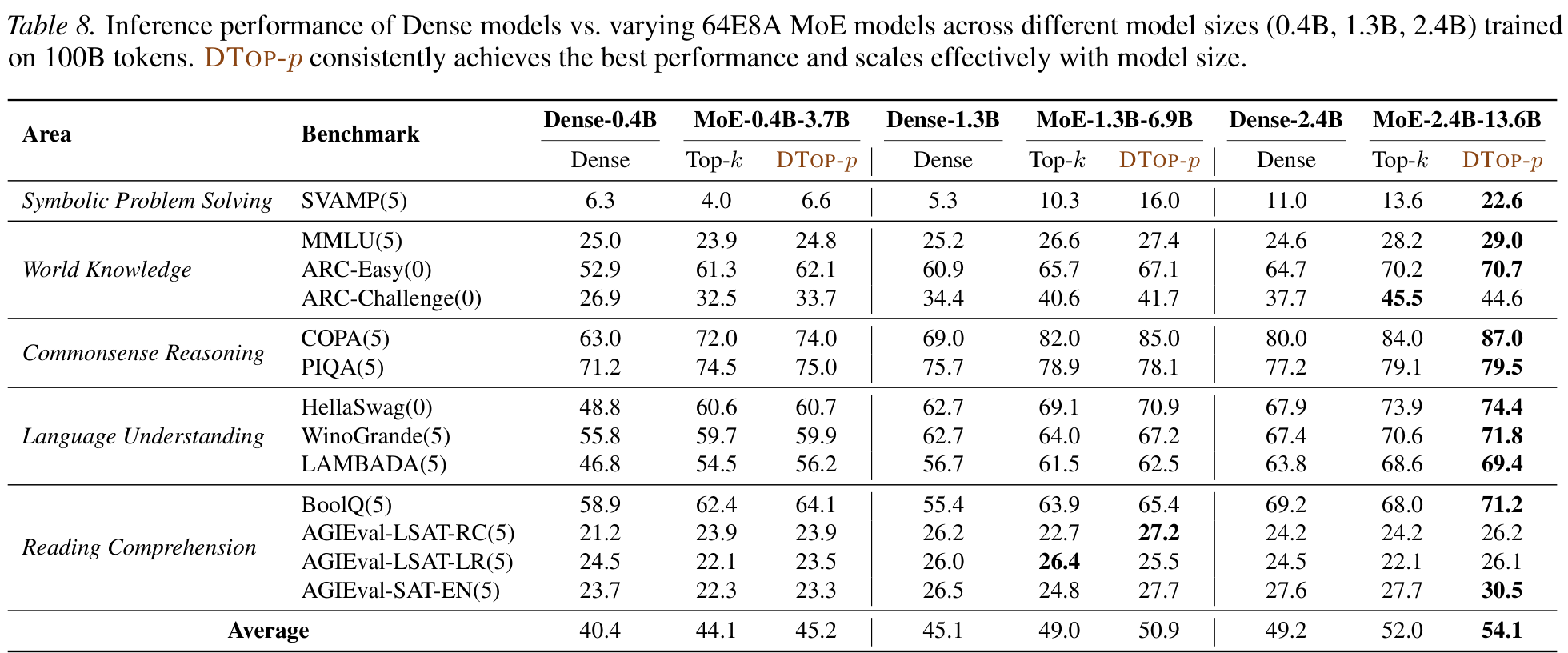
- DTop-p reconciles token-adaptive routing with strict compute control via PI control — no gradient needed for the threshold.
- Beats Top-k & fixed Top-p on LLMs and DiTs; robust scaling across granularity, model & dataset size.